R软件stm包实操 比LDA更强大的文本处理程序包详解,助力网络与信息安全软件开发
随着大数据时代的深入发展,文本数据已成为网络与信息安全领域不可或缺的情报来源。从海量的网络日志、社交媒体言论到安全报告,有效挖掘文本中的主题与模式对于威胁检测、舆情监控和态势感知至关重要。在文本主题建模领域,潜在狄利克雷分配(LDA)模型曾长期占据主导地位。如今有一个更强大的工具已经上线——R语言中的结构化主题模型(Structural Topic Model, STM)程序包。它不仅在建模能力上超越了传统LDA,更因其灵活性和对元数据的整合能力,为网络与信息安全软件开发注入了新的活力。本文将深入解说STM包的核心优势,并提供基础实操指南。
一、为什么STM比LDA更强大?
传统LDA模型将文档视为词的集合,并假设文档主题分布的先验是固定的(对称狄利克雷分布)。虽然经典,但其局限性也显而易见:
- 无法融入文档级元数据:LDA无法直接利用与文档相关的额外信息,如文档的作者、发布时间、来源网站类型(在安全领域,可能是攻击类型、威胁等级、IP归属地等)。这些元数据往往包含关键的结构性信息。
- 主题内容固定不变:LDA假设词汇在主题中的分布不随文档特征变化。而在现实中,同一个主题(如“网络钓鱼”)在不同来源(如社交媒体与暗网论坛)或不同时期,其表达用词可能显著不同。
STM模型正是为解决这些问题而生。其核心强大之处在于:
- 结构化先验:STM允许文档的主题比例(主题流行度)和主题本身的内容(词分布)都受到文档元数据的直接影响。这意味着我们可以建模“某个特定来源的文档更倾向于讨论某个主题”,或者“在某个时间段,某个主题的表述方式发生了演变”。
- 丰富的协变量:可以同时引入影响主题流行度(
prevalence)和主题内容(content)的协变量(即元数据),使得模型更贴近真实数据生成过程。
对于网络与信息安全应用,这意味着我们可以构建更精细的模型。例如,分析黑客论坛数据时,可以建模“攻击技术”这一主题的讨论热度如何随论坛板块(元数据)变化,以及“勒索软件”主题的用词在攻击事件爆发前后(时间元数据)有何不同。这为追溯威胁源头、刻画攻击者画像提供了更强大的分析工具。
二、STM包基础实操步骤
以下是在R环境中使用stm包进行文本主题建模的一个简明流程。假设我们已有一个来自安全告警日志的文本数据集 security_data,包含文本字段 text 和元数据字段 source(来源)、date(日期)。
步骤1:环境准备与数据预处理
`r
# 安装并加载必要的包
install.packages("stm")
install.packages("quanteda") # 用于文本处理
library(stm)
library(quanteda)
1. 文本预处理:创建文档-词矩阵(DFM)
假设 df 是数据框,包含‘text’和元数据列
processed <- textProcessor(df$text,
metadata = df,
lowercase = TRUE,
removestopwords = TRUE,
removenumbers = TRUE,
removepunctuation = TRUE,
stem = TRUE) # 词干化
2. 准备STM分析所需的数据结构
out <- prepDocuments(processed$documents,
processed$vocab,
processed$meta,
lower.thresh = 5) # 剔除出现少于5次的词
out对象包含了STM所需的文档、词汇表和元数据
`
步骤2:运行STM模型
这是最核心的一步,我们可以指定元数据如何影响模型。
`r
# 简单模型:仅指定主题数K,无元数据(此时类似于LDA)
model_lda <- stm(documents = out$documents,
vocab = out$vocab,
K = 10, # 假设我们寻找10个主题
data = out$meta,
max.em.its = 75, # 最大迭代次数
init.type = "Spectral") # 推荐初始化方法
结构化模型:让“来源(source)”影响主题流行度
model_stm <- stm(documents = out$documents,
vocab = out$vocab,
K = 10,
prevalence = ~ source, # 关键!主题比例受source影响
data = out$meta,
max.em.its = 75)
更复杂的模型:同时让来源影响主题流行度,并让日期影响主题内容
modelstmadv <- stm(documents = out$documents,
vocab = out$vocab,
K = 10,
prevalence = ~ source,
content = ~ date, # 关键!主题内容随时间变化
data = out$meta,
max.em.its = 75)`
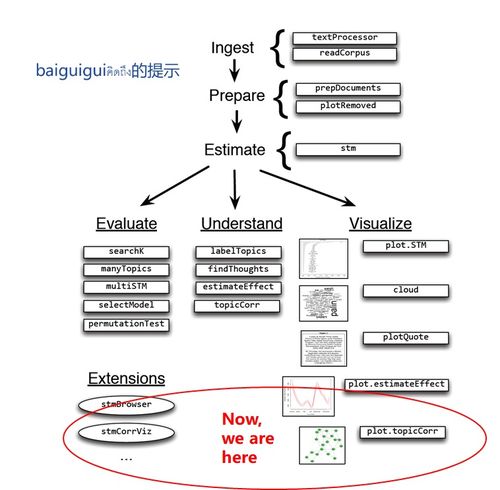
步骤3:模型结果解读与可视化
stm包提供了丰富的函数来理解和展示结果。
`r
# 1. 查看高频词和主题标签
labelTopics(model_stm, topics = 1:10)
# 它会显示每个主题下概率最高、FREX值最高(独特且频繁)的词,帮助理解主题含义。
2. 可视化主题间关系(基于语义相似度)
library(ggplot2)
mod.out.corr <- topicCorr(model_stm) # 计算主题相关性
plot(mod.out.corr) # 绘制主题网络图,关联紧密的主题会聚集在一起。
3. 评估元数据效应(例如,不同来源对主题1流行度的影响)
prep <- estimateEffect(1:10 ~ source, modelstm, meta = out$meta)
summary(prep) # 查看统计显著性
plot(prep, covariate = "source", model = modelstm, method = "difference",
topics = 1, # 绘制主题1
xlab = "来源A相比来源B在主题1上的流行度差异") # 可视化效应
4. 可视化主题内容随元数据的变化(如果指定了content协变量)
plot(modelstmadv, type = "perspectives", topics = c(1, 2))
# 这可以展示同一个主题下,不同日期(或其它content协变量)的用词差异。
`
三、在网络与信息安全软件开发中的应用启示
将STM整合进安全软件开发,可以极大地提升系统的智能分析能力:
- 动态威胁情报挖掘:自动化处理来自开源情报(OSINT)、暗网论坛、漏洞数据库的文本,利用时间、来源等元数据建模,实时发现新兴攻击话题、技术演进趋势和活跃威胁组织。
- 智能化日志分析:安全运营中心(SOC)每日处理海量告警日志。STM可以对这些日志的文本描述进行主题建模,并结合告警等级、资产类型、地理位置等元数据,自动聚类出高优先级的攻击模式(如“针对金融部门的针对性钓鱼”主题),辅助分析师快速聚焦。
- 舆情与内部风险监控:在内部通讯或公开社交媒体数据中,通过建模主题流行度与部门、时间段的关系,及时发现异常讨论热点(如可能的数据泄露讨论、不满情绪聚集),实现 proactive 的风险防范。
- 生成式安全报告辅助:利用STM模型识别出的核心主题及其代表性文档,可以自动生成安全周报/月报的初稿,概括本期主要安全事件类型、影响范围和演变情况。
###
R语言的stm包通过引入结构化先验,成功突破了传统LDA模型的局限,为处理复杂的、带有丰富元数据的文本数据提供了强大武器。对于网络与信息安全这一高度依赖上下文和关联信息的领域而言,STM不仅仅是一个“更强大的主题模型”,更是一个能够将非结构化文本与结构化元数据深度融合的分析框架。从研究到开发,掌握STM的实操,意味着能够为下一代智能安全分析软件打造更敏锐的“文本感知”能力。赶紧上手尝试,让您的安全数据“开口说话”吧!
如若转载,请注明出处:http://www.vertiv-will.com/product/48.html
更新时间:2026-06-18 12:57:44